Design
This diagram illustrates the workflow from model generation to inference service deployment.
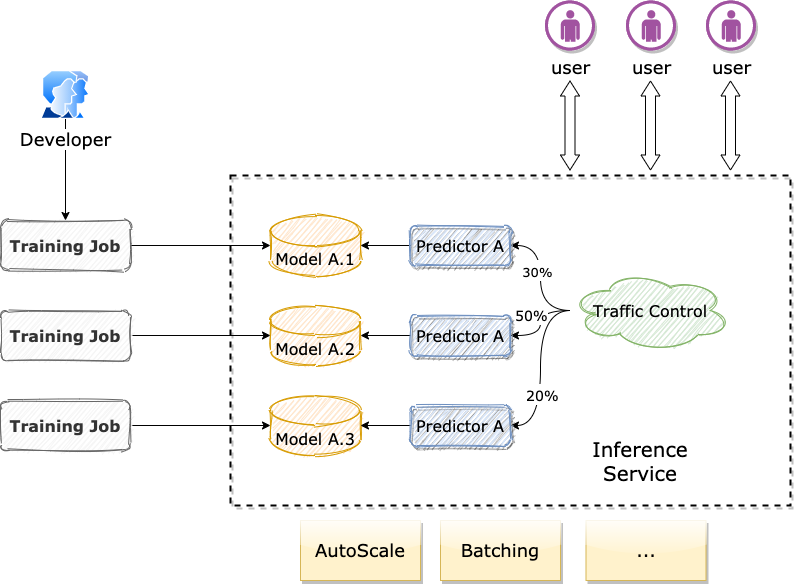
An inference CRD describes the inference framework used for serving the model (TensorRT, Triton etc.), predictor(s) template with its served model-version and deployment strategies, such as auto-scaling, batching...
The Inference Controller watches the Inference CRD and does the following steps.
- Retrieve the latest Inference CRD and creates an entry in cluster dns host for accessing inference.
- Create predictors as specified in inference CRD, set framework-related spec and create a deployment for each,
- Each deployment will be injected with a model-loader init container to load model artifacts from previously build image.
- An inference service can serve more than one model version at a time. Each model-version is hosted by its own predicator.
- User is able to specify the traffic percentage of each predictor. We use Istio VirtualService to distribute traffic across predictors, if inference has more than one predictor.
- More features are upcoming... see our ROADMAP for details.